

Some forlorn news for Marti’s fans: I’m going to stop working on this project indefinitely, first to focus on paid work, and then to focus on grad school.
It’s been a blast dusting off my coding skills and keeping abreast of the latest developments in LLMs and speech-to-text. I’ve also appreciated having this project as an opportunity to stay engaged while figuring out my next steps. However, now that I know I’ll be attending grad school in autumn, I want to save up some cash. Sadly, this means I won’t be able to give Marti the love and attention that the project deserves.
Speech-to-phoneme implemented
In addition to the work on Marti that I’ve already written about, I implemented a speech-to-phoneme model, which is a better approach for language learning than speech-to-text. I was disappointed to discover that this particular model generated imperfect results and didn’t add punctuation or segmentation.
In response to audio that came from a person saying aloud “A MAN SAID TO THE UNIVERSE SIR I EXIST”, the model generated “ɐ m æ n s ɛ d t ə ð ə j uː n ɪ v ɚ s s ɚ aɪ ɛ ɡ z ɪ s t”. Manually segmenting this output, the result was “ɐ mæn sɛd tə ðə juːnɪvɚs sɚ aɪ ɛɡzɪst”. You can run this transcription through an IPA reader to hear what it would sound like. It’s not entirely off1 but it’s not perfect, which would cause Marti to give unnecessary pronunciation improvements.
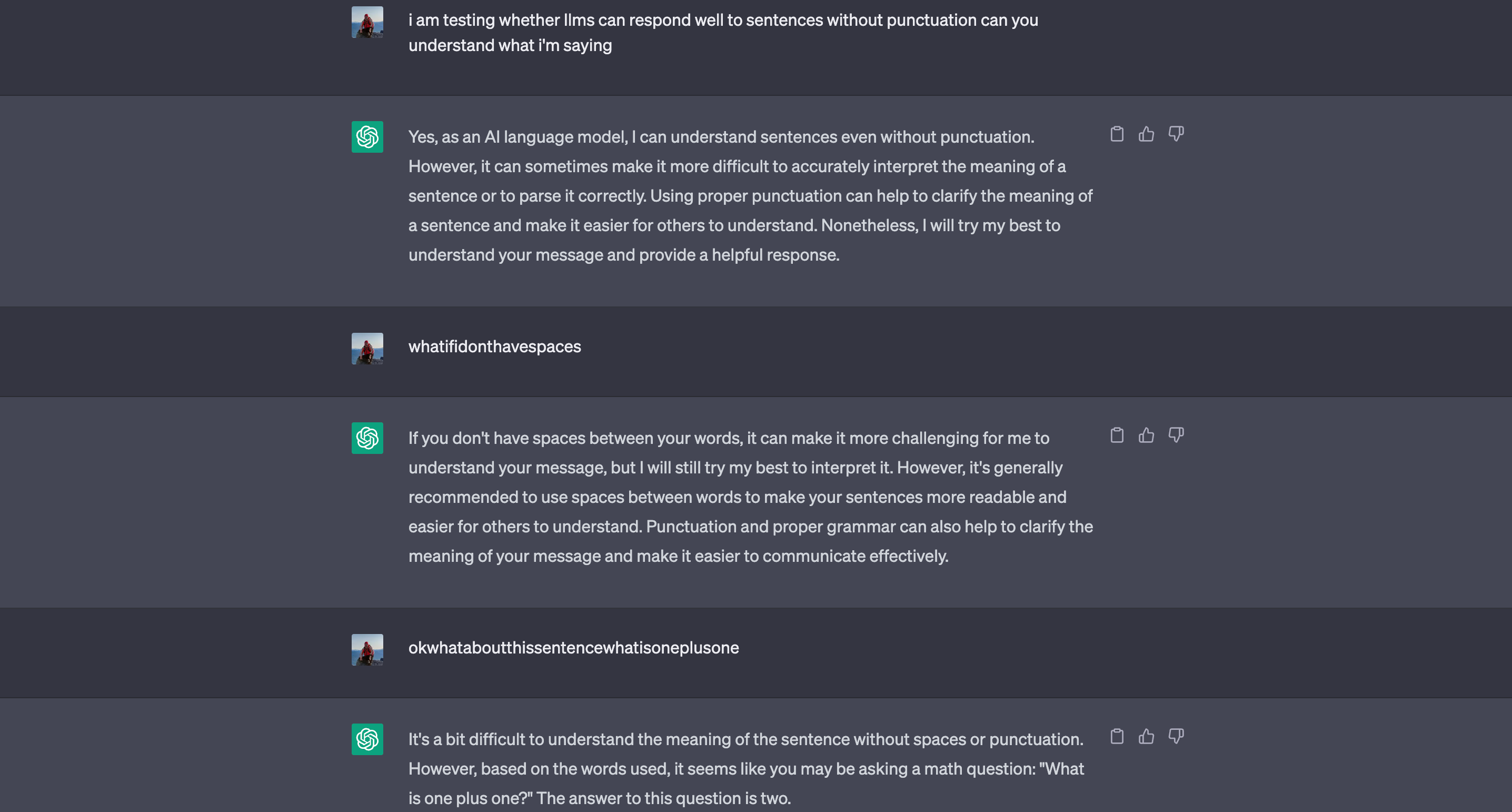
More annoying than the imperfect transcription is the fact that the Wav2Vec2Phoneme model doesn’t properly punctuate or segment speech. Although LLMs can parse text without punctuation and even without spaces, ChatGPT admits that it has difficulty parsing text without these components.
I’m still convinced that speech-to-phoneme is a better approach to ASR for language-learning bots than speech-to-text but I am no longer convinced that the current state of STP models is advanced enough to make this approach viable out of the box. Likely, a team working on language-acquisition tech would need to develop and train a new STP model, which I simply don’t have the resources to do right now.
I won’t publish a corresponding branch on Marti’s GitHub because I didn’t do much code iteration. If you’re interested in trying out the model for yourself, you can set it up as explained in the relevant HuggingFace checkpoint.
Note that you’ll need to pip install soundfile and librosa as well as espeak via phonemizer, which is not clear from the model card. Also note that although the demo example in the model card says:
# => should give ['m ɪ s t ɚ k w ɪ l t ɚ ɪ z ð ɪ ɐ p ɑː s əl l ʌ v ð ə m ɪ d əl k l æ s ɪ z æ n d w iː aʊ ɡ l æ d t ə w ɛ l k ə m h ɪ z ɡ ɑː s p ə']It should in fact give ɐ m æ n s ɛ d t ə ð ə j uː n ɪ v ɚ s s ɚ aɪ ɛ ɡ z ɪ s t
Retrospective
Since I’m putting Marti on an indefinite pause, I’ve been reflecting on what went well and what I will do better on my next project. I find it helpful to reflect and structure my reflections on these topics so that I can continue to improve my workflows and processes.
Did well
Overall, I’m very happy with the work that I did on Marti and what I was able to accomplish while working on this for just a few hours every week. I’m especially proud of my analyses, both my analysis of Marti v0 and speech-to-text benchmark.
I think there are three aspects of my work on Marti where I was particularly successful:
Identifying and justifying a useful niche
Making strategic decisions
Organizing, structuring, and documenting my work
Identifying and justifying a useful niche
I spent a couple of weeks brainstorming, discussing, and iterating on ideas for projects to work on before I settled on Marti. I tried to emphasize a fast iteration philosophy and was happy that I didn’t waste time by selecting a project direction that would’ve been uninteresting or unimpactful. I also found that writing about why I choose to do this project made it easier for me to communicate with others about why I was spending my time on this and helped me motivate myself.
I still believe that language acquisition is an area where LLMs can be very impactful and better the world. Even though I don’t have the resources to successfully execute this vision, I’m excited about the work that companies like Duolingo (with the creation of Duolingo Max) and Speak are doing in this space.
Making strategic decisions
Beyond that high-level direction, I think that I made a lot of good strategic decisions about the development process of Marti. Some examples:
Getting an MVP out as early as possible, which enabled me to talk more concretely about what I was working on and identify the areas that needed iteration
Improving one part of the system at a time, which allowed me to iterate quickly and not get bogged down with context switching
Pursuing out-of-the-box solutions and managed services first before exploring custom models, which allowed me to quickly explore a large area
These types of strategic decisions helped me to work on the things that were most useful and gain the broadest understanding of this problem space.
The one strategic blunder that I made was thoroughly pursuing the speech-to-text option and working very hard on the speech-to-text benchmark even though I knew I’d be exploring a different direction. I’m still glad that I worked on and published the benchmark because it helped me gain some traction and interest from collaborators but it certainly slowed down my development of Marti.
Organizing, structuring, and documenting my work
More tactically, I did a good job of making sure that Marti was well-organized, structured, and documented. I heard from multiple interested users, hobbyists, and potential collaborators that they appreciated how easy it was to understand what Marti did, how to use Marti, and the development process for it. By writing about Marti, I was able to both communicate about the project efficiently and structure my own thinking, which helped me to execute better on the project.
Will do better next time
It’s not all rainbows, sunshine, and self-aggrandizement, however. There are a few lessons that I’ve taken away from this project:
I want to spend more time developing and less time writing
I will be more productive if I take more advantage of advanced coding tools
I will be happier with my code if I use more Python and OOP best practices
More developing
Although writing so thoroughly about this project carried a couple of advantages (as discussed above), it did end up getting in the way of my development work. Especially when working on the more significant blog posts, I spent a lot of time polishing and perfecting the graphics and text. This is undoubtedly important to do when writing for communication but was excessive and ended up being a distraction with diminishing returns. I could have moved faster if I had simply shipped imperfect writing and gone back to coding.
Advanced tooling
I ended up significantly improving my tooling game as a result of this project, moving to VSCode for my IDE, using pylint and black for formatting, refamiliarizing myself with git, etc. This was part of my intention with having a personal project like Marti to work on since I had the freedom to experiment and the spaciousness to find the right tooling setup for me.
However, I think I could have been even more effective if I had used more advanced coding tooling. Although I did end up taking advantage of GitHub Copilot to some extent, I still found myself Googling and searching StackOverflow for syntaxes and common issues, rather than simply letting Copilot auto-populate code for me. When I did use Copilot, I was continuously impressed with how much faster I was able to iterate and develop, and how magical the experience was.
Similarly, I suspect I could have saved myself some time and effort if I had simply asked ChatGPT to generate some of the code that I ended up writing myself. This would have let me focus on areas where I could be more impactful, rather than wasting time rehashing solved problems.
Best practices
I also found myself wishing that I had tackled certain problems with more Python and especially object-oriented programming best practices. I half-jokingly referred to the code for my benchmark as 300+ lines of spaghetti code, since so much of it doesn’t follow best practices. Although my code got the job done, it is now hard to parse and not very reusable for other people wishing to benchmark different speech-to-text options. This makes the project less useful than it could have been for others with specific speech samples.
I was able to complete the development faster because I didn’t refactor the program when I realized it was growing unwieldy. However, this did negatively impact the value of the program. In the future, I will do a better job of identifying when I should start using best practices earlier, even if they slow down development, to make sure that my code will be readable and reusable.
fin
I’ve deeply enjoyed working on Marti and have learned so much from this project. I’m looking forward to tracking the language acquisition technology space, especially as more and more companies incorporate LLMs into their product. I’d be excited to work with a team that is developing in this area so that I can apply my learnings from working on Marti.
Since this is likely my last post on this Substack, I won’t provide a “subscribe” call to action. Instead, if we’re not already connected on LinkedIn, I invite you to connect with me. You can also email me at danny [dot] leybzon [at] gmail [dot] com if there’s anything about Marti that you’re interested in discussing.
Manually transcribing the same audio, I got “ə mæn sɛd tu ðə juːnəˌvɝs sɝ aɪ ɪɡˈzɪst”. This is very close to the model’s transcription of “ɐ mæn sɛd tə ðə juːnɪvɚs sɚ aɪ ɛɡzɪst”, though there are enough differences that a system comparing them might wrongly recommend pronunciation improvements to the speaker