A Comprehensive* Speech-to-Text Benchmark**
I wrote 300+ lines of spaghetti code and all I got was this lousy table

* Calling my experiment “comprehensive” is an exaggeration. I tested 14 different speech-to-text, automatic speech recognition, and transcription models and services. This is undoubtedly a long list—and much longer than I’ve seen in any other benchmark—but I’m sure there are services I didn’t discover and plenty of models I didn’t choose to implement. Still, the options I considered seem to be the most commonly used, so I hope this post still provides some value to readers
** Calling it a benchmark is undoubtedly less of an exaggeration. However, I think it’s still worth highlighting a major disclaimer about this dataset: I used a ~50 sample set of simple Spanish sentences that I recorded and transcribed. A more involved benchmark would have used data from the standard Common Voice Datasets, which would have had more samples and more variation
Ok, now that we’ve gotten all of the disclaimers out of the way, let’s talk about what we’re here to talk about: benchmarking the myriad speech-to-text (STT) services, models, and APIs.
As part of my work to improve Marti’s hear module, I decided to test various STT options to select the best one for my use case. A couple of weeks into setting up the benchmark, I realized that I wanted to take Marti’s hear module in another direction. I decided to go ahead with publishing my benchmark out of the hope that other developers will get some value out of my results or methodology. If you’re curious about my methodology or raw data, you can check out the GitHub repo for this benchmark.
As readers may expect, the results of my benchmark were decisive and conclusive:
there is no single best option for speech-to-text
I found that, depending on the developer’s priorities for their use case, the speech-to-text options would stack up differently. When optimizing for speed, locally-run models like Alpha Cephei’s Vosk or Picovoice’s Leopard ran the fastest. For accuracy, OpenAI’s hosted Whisper, AssemblyAI, and Microsoft Azure’s Speech to Text made the fewest errors.
Taking into account more variables—such as price, ease of use, and whether it’s possible to run the model locally—it becomes clear that each developer must determine for themselves which option best fits their use case. Hopefully, the results of this benchmark will help narrow down options for you, based on the criteria that you’re using to evaluate your choices.
Results
As part of my benchmark, I analyzed the accuracy and speed of the various options. In addition to these testable factors, I also looked at:
Production Readiness: Does this option seem well-suited for supporting a production application?
Price: How much would this option cost for various use cases?
Where It Runs: Can this model be run anywhere or is it only accessible as a managed service with an API?
Ease of Setup: How easy did I find it to set up access to this option?
I dive into each of these factors in greater depth below, but first, I’m going to answer the question on everyone’s mind:
What’s the best option for speech-to-text?
The Best Option
As alluded to in the introduction, there is no clear winner among the plethora of speech-to-text options. The “best” option for speech-to-text technology is entirely dependent on the use case and priorities of the developer. There, were, however, some top-performing tools that I want to highlight for their various strengths:
Well-Rounded Hosted Service: OpenAI’s Hosted Whisper
First and foremost, I want to highlight how impressed I was with OpenAI’s hosted version of their Whisper model. It was consistently highly accurate and decently fast, the easiest to set up, and among the least expensive options. If you’re ok using a hosted service, I would start with OpenAI’s Whisper and use it as the standard against which you can compare your other options.
Also Good Hosted Options: Deepgram, AssemblyAI
Deepgram and AssemblyAI are certainly the runners-up in this analysis compared to OpenAI’s Whisper but they’re not too shabby. Of the two, I’d pick Deepgram as the first tool to explore because it:
Had only slightly worse speed and accuracy than OpenAI’s Whisper
Was almost as easy to set up
Is relatively inexpensive
Might be more production-ready than OpenAI’s relatively new offering
I was disappointed with AssemblyAI’s speed in this benchmark1. The team there does great work on using AI for STT but it didn’t come across in this analysis, likely because their offering is specifically oriented towards transcription rather than real-time speech-to-text. This means that they ended up being extremely slow and very inconvenient to use. They did have better accuracy than Deepgram but were the worst-performing option among the five which tied for first place.
Top-Performing Local Models: Whisper, Picovoice Leopard
It’s hard to pick a favorite between the two top-performing local models, especially because I don’t feel like I gave either of them a fair shake.
In the case of Whisper, I used a “tiny” Whisper model, which allowed it to remain competitive on speed but tanked its accuracy. A larger model would certainly have been more accurate but not fast enough on my crappy hardware. There’s great work being done on accelerating Whisper2 which would make it feasible to use larger and more accurate models for real-time use cases. If you want a locally-running model, it’s worth experimenting with Whisper.
In the case of Leopard, there is was3 no Spanish language option, which tanked its accuracy. However, the model had the lowest median latency, which indicates that it would be a great option for edge, on-device English speech-to-text applications. It’s also the only on-device model that runs as a service offering, indicating that you can likely get superior support for it compared to purely open-source offerings.
The Cloud Options: Azure, GCP, AWS
All three options offered by major cloud providers have high sticker prices compared to best-of-breed point solutions like OpenAI’s Whisper, Deepgram, and AssemblyAI. They’re all also middling compared to other options in terms of speed and accuracy. On the positive side, they’re all highly production ready, and Microsoft Azure and Google Cloud Platform (GCP) were both very easy to set up. Overall, I’d consider starting with the point solutions described above, unless you have a particularly well-discounted enterprise contract with one of these cloud providers.
I was surprised to find that, among the three major cloud players, Azure was well ahead of the pack in terms of accuracy. Although it was slower than GCP, it was equally easy to set up.
GCP performed decently in terms of both speed and accuracy, neither leading the pack nor falling too far behind.
The biggest gripe that I have with a cloud service is with Amazon Web Services’ (AWS) Transcribe offering. AWS’s offering is particularly slow because, rather than being able to directly send audio to the transcription service, users have to first upload their data to S3, wait for it to finish uploading, and only then initiate a transcription call. Of the three services, it was by far the hardest to set up. I hope that AWS improves its speech-to-text service because this seems like a big gap in its offerings.
Analysis
Accuracy
I started by analyzing accuracy, which I defined using a standard STT metric: Word Error Rate (WER)4. I decided to start with accuracy rather than speed because I have a minimum threshold for accuracy5. Other use cases may have a minimum required speed, in which case you may prefer to start with "speed" in your analysis and filter to only the options which are fast enough to be worth exploring.

I found a wide range of WER scores by API. The worst-performing APIs—like Houndify, Picovoice, and Sphinx—either didn’t have Spanish-language options or made accessing those options prohibitively tricky. Since the latter two had outliers that skewed the graph so significantly, I decided to create the visualization again, without those two worst-performing options

From here, I was happy to see quite a few options with WER distributions generally around 0, allowing for a few outliers. I decided that I would take the five APIs with WERs of 0 for over 75% of samples6 and evaluate their speeds.
Speed
I analyzed speed by tracking how long it took for a service to return text after I uploaded audio. Similar to the Accuracy section, I used boxplots to compare the distributions of these latencies for each option.
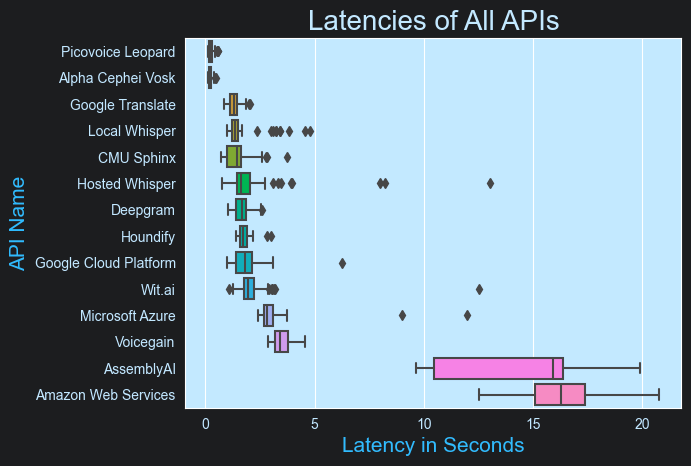
An interesting finding from this analysis was that the fastest APIs tended to be models that ran locally (i.e. Picovoice, Vosk, Whisper, and Sphinx) rather than hosted services (e.g. Voicegain, Azure, Wit.ai, or GCP). It’s hard to make apples-to-apples comparisons between local models and hosted services. The former is impacted by the hardware of the machine running the benchmark and the latter is impacted by potential differences in network latencies. Optimally, a developer will benchmark the options on hardware and networks representative of their deployment environment.
After reviewing the analysis for the whole dataset, I filtered to only look at the latencies of the five best-performing APIs:

As we saw in a previous visualization, AssemblyAI had high latencies, so we can eliminate it as an option. Among the remaining options, they all perform in a similar range, with most of the responses coming back in under 3 seconds.
However, I quickly realized that just looking at accuracy and speed wouldn’t give me a full picture of the tradeoffs involved in each option.
Other Considerations
Although I set out to measure accuracy and speed, I ended up realizing that this was insufficient. Taking into account only the benchmarkable factors would have been looking for my keys where the light is, and I would’ve missed some critical considerations.
Production Readiness
One such consideration came up as soon as I looked at the above graphic of “Latencies of Highest Accuracy APIs”. Looking just at this visualization, the natural conclusion is that the Google Translate API is the best choice, being a high performer in terms of both accuracy and speed. A casual observer would naturally conclude that Google Translate is a great choice to use as a speech-to-text tool for commercial production.
And a casual observer would be seriously mistaken.
That’s because the Google Translate API (more properly the Chromium Cloud Translation API) isn’t meant to be relied on as a production-ready service. By default, the service can be called with a key that “may be revoked by Google at any time”. Although users can generate their own key, they’re limited to 50 requests per day, which is likely insufficient for most production applications.
None of the other services have quite as glaring of a production-readiness issue, but they are likely to have different capacities for supporting production applications. I didn’t talk to any vendor while preparing this blog post, but if I was interested in using a speech-to-text service as part of a product I was offering to customers, I would want to have SLAs in place and be confident that the service provider could meet them.
Price
Another consideration is price. Although each of the services I tested has a free trial or tier, most require payment for usage above a certain amount.
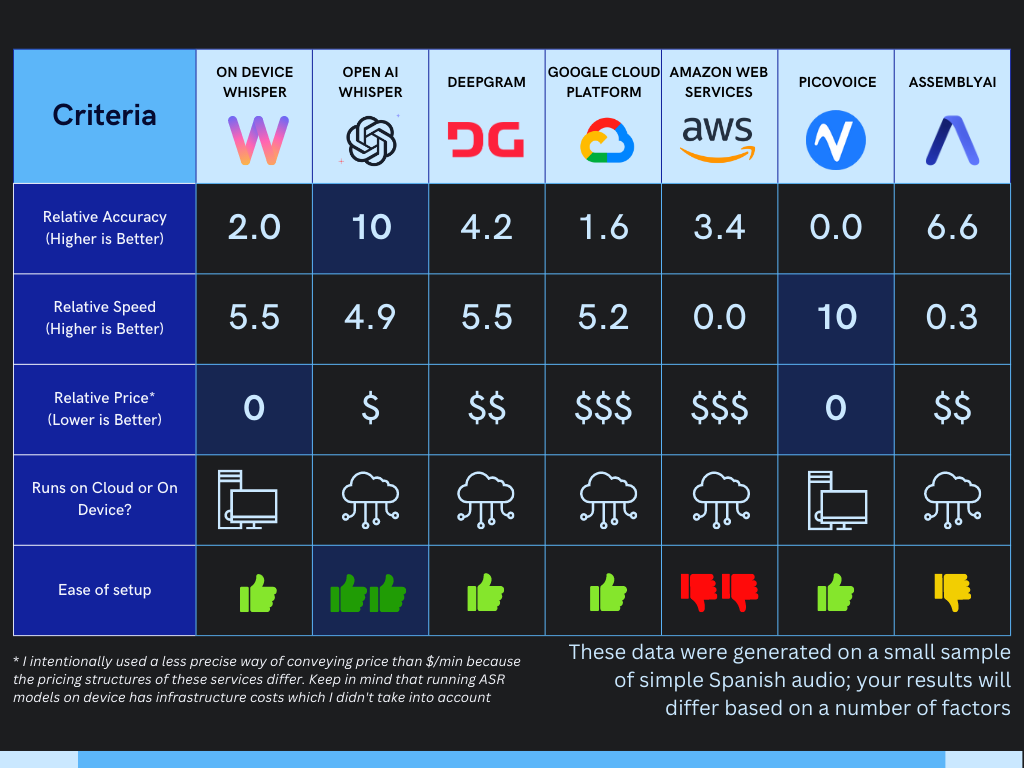
In the table at the top of the page, I came up with a rough sketch for the relative prices for seven of the options. Fortunately, it’s pretty easy to compare the different options apples-to-apples since, for the most part, they offer usage-based pricing based on the amount of audio time being transcribed.
However, this comes with a few caveats:
Although services mostly all offer the same general pricing model (dollars per minute of audio to transcribe), their pricing structure varies widely. The amount of free transcription, the rate of bulk discounting, etc, all affect the actual costs a developer would pay for using a managed service
In addition to the bulk discounting offered on the website for self-serve usage, there’s also often an ambiguous “enterprising pricing” option. This makes perfect comparison impossible since enterprise pricing is generally intentionally obfuscated
I treated open-source models (i.e. Whisper, Sphinx, and Vosk) as having 0 cost but this is not entirely accurate. Speech-to-text requires a model running on some computer somewhere. Depending on the deployment architecture, this may be a customer’s computer, a developer’s server, or a vendor’s server. This infrastructure has a cost, but it’s challenging to quantify because it is highly deployment-specific
All in all, although the pricing I shared is directionally-correct for the 7 options in the table at the top, ultimately pricing varies by application.
Where It Runs
Much simpler to evaluate but still highly specific to a particular application is where a model runs. Models can be run locally—either in the developer’s environment or the end user’s—or in the vendor’s environment. This has latency implications, as discussed in the Latency section, and pricing implications, as discussed in the Price section. It also potentially has implications for the types of use cases appropriate for a particular option.
For instance, if I want to use speech-to-text for transcribing videos to turn into blog posts, it doesn’t matter whether the model is running locally or in the cloud. However, if I want to create a voice-enabled vacuum cleaner that works even when disconnected from the internet, I’ll need to be able to run the model locally on my device.

For the most part, locally-running models are open source. There is one interesting exception to this: Picovoice’s Leopard STT offering. Picovoice Leopard runs locally on the user’s device, but setup requires an access key and internet access during setup to validate that key. This interesting approach allows Picovoice to offer all of the benefits of on-device STT (speed, no network requirements, no developer-managed compute infrastructure) while still enabling them to provide a vendor-managed service and to profit from their model.
Ease of Setup
The final factor is almost entirely subjective and I couldn’t think of a way to create an objective measure for it. Developers have different levels of experience with different tools, access these services from different programming languages, etc. However, I evaluated how long it took me to implement the various options, and used that as a proxy for how easy they are to set up.
In the category of locally-run models, I found Picovoice Leopard and Whisper straightforward to set up, while Vosk provided some difficulties, and Sphinx required quite a bit of tinkering. For Vosk and Sphinx, setting up the language-specific models for Spanish was quite challenging. Conversely, Whisper doesn’t have separate models for different languages, so setting it up was easy. Leopard also doesn’t have separate models for different languages, but this just caused their model to severely underperform when it came to Spanish.
Across the vendor-managed services, there was a wide range of ease of setup. Some, like OpenAI and Deepgram, have great, simple Python SDKs that make accessing their APIs easy. AWS also has a great Python SDK, but the developer experience of accessing the AWS Transcribe service is awful. On the low end of usability, Voicegain’s Python SDK is very rudimentary, and AssemblyAI doesn’t have an actively-maintained Python SDK and recommends directly hitting their HTTP endpoints.
Conclusion
If you’ve made it this far, congratulations and thank you for your support. As I mentioned in the introduction, before I’d even completed this benchmark, I realized that its results were likely irrelevant to my work with Marti. Still, I hope that some developers out there find my musings, ramblings, and results helpful in making decisions about which speech-to-text technologies to use in their projects.
If you’re interested in reading about my development process for Marti, an AI-powered language tutor, subscribe below. If you found this post interesting, you may appreciate my upcoming post about using speech-to-phoneme models.
Since running this benchmark, I’ve discussed my results with a few people and it sounds like AssemblyAI will soon have a much better STT option. I can’t speak to the performance of a tool I haven’t personally benchmarked but you can test it for yourself with a sneak preview of their upcoming real-time offering
One project on accelerating Whisper that I’ve heard a lot about is whisper.cpp, which reimplements Whisper in C++ rather than in less-performant Python
In the time since I published this post, Picovoice has released a Spanish-language option for Leopard. Crazy how quickly this space moves!
There’s a compelling paper that expounds that Match Error Rate (MER) and Word Information Lost (WIL) are superior metrics for evaluating speech recognition tasks. I use WER in this post because it continues to be the most commonly used metric and because, for this dataset, I found that WER, MER, and WIL correlate >.98. I retain my MER and WIL calculations in the raw dataset
Some options had ridiculous results, like transcribing "perdón" as "Avalon". No matter how fast an AI tutor is, if they’re that bad at understanding you, you’re not going to learn a new language
Microsoft Azure, Wit.ai, Google Translate, OpenAI’s hosted Whisper, and AssemblyAI
Are speech to phoneme models language agnostic? As in, if I’m a native Spanish speaker, will it “understand” my accent?